

Обучение Коши
В работе [6] развит метод быстрого обучения подобных систем. В этом методе при вычислении величины шага распределение Больцмана заменяется на распределение Коши. Распределение Коши имеет, как показано на рис. 5.3, более длинные «хвосты», увеличивая тем самым вероятность больших шагов. В действительности распределение Коши имеет бесконечную (неопределенную) дисперсию. С помощью такого простого изменения максимальная скорость уменьшения температуры становится обратно пропорциональной линейной величине, а не логарифму, как для алгоритма обучения Больцмана. Это резко уменьшает время обучения. Эта связь может быть выражена следующим образом:

Распределение Коши имеет вид

где Р(х) есть вероятность шага величины х.
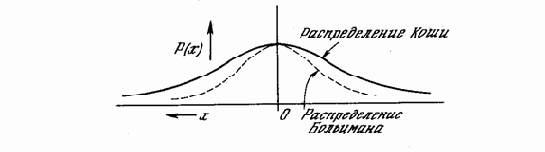
Рис. 5.3. Распределение Коши и распределение Больцмана
В уравнении (5.6) Р(х) может быть проинтегрирована стандартными методами. Решая относительно х, получаем
xc = r T(t) tg(P(x)), (5.7)
где r – коэффициент скорости обучения; хc – изменение веса.
Теперь применение метода Монте Карло становится очень простым. Для нахождения х в этом случае выбирается случайное число из равномерного распределения на открытом интервале (–p/2, p/2) (необходимо ограничить функцию тангенса). Оно подставляется в формулу (5.7) в качестве Р(х), и с помощью текущей температуры вычисляется величина шага.